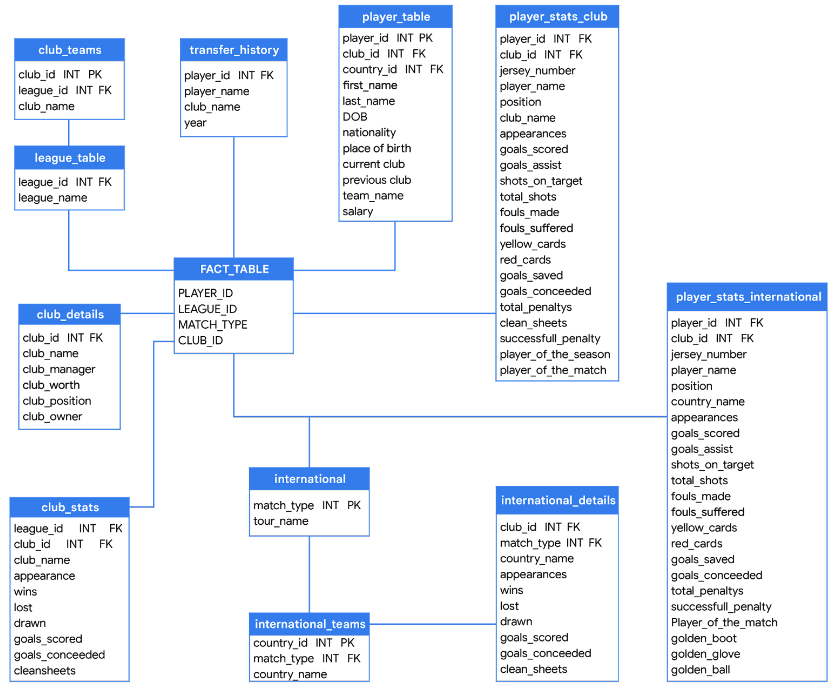
Collection of documents Single table with keys and values
Collections of nodes and relationships
Datadesign
Normalized relational or dimensional data warehouse.
Denormalized document, wide column or key value
Denormalized entity relationship
Optimized
Optimized for storage
Optimized for compute
Optimized for relationships
Querystyle
Language: SQL
Language: many Uses object querying
Language: many Uses object querying
Scaling
Scale vertically
Scale horizontally
Hybrid
Implementation
OLTP business systems, OLAP data warehouse
OLTP web/mobile apps
OLTP web/mobile apps
Types of data models
Data models describes how data is represented.
Relational models
= A relational model organizes data into one or more tables (or "relations") of columns and rows, with a unique key identifying each row.
Rows are also called records or tuples. Columns are also called attributes.
Generally, each table/relation represents one "entity type" (such as customer or product). The rows represent instances of that type of entity (such as "Lee" or "chair") and the columns representing values attributed to that instance (such as address or price).
Dimensional model
Star schemas
A schema consisting of one or more fact table that references any number of dimension tables
Snowflake schemas
An extension of a star schema with additional dimensions and often sub-dimensions
Schema is a way of describing how something such as data is organized.
Denormalized/NoSQL schemas
Document model: JSON, XML, Binary JSON (BSON)
Graph model
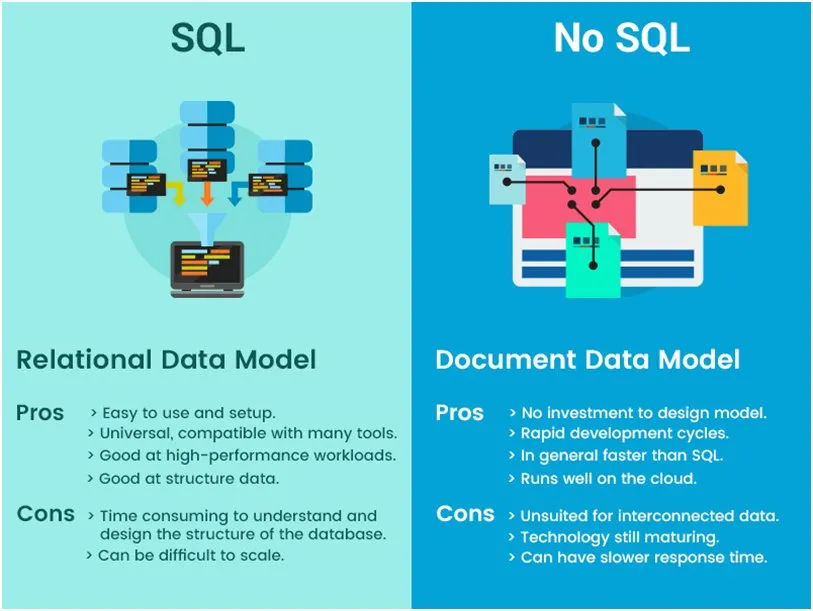
SQL vs. No SQL
Key elements of database schema
the relevant data
names and data types for each column in each table
consistent formatting
unique keys
Transactional & Analytical Processing
Typically, there are two types of workloads that databases are optimized for, transactional processing and analytical processing:
online transaction processing (OLTP)
often called operational databases
databases that have been optimized for data processing (for data entry purposes)
BASE criteria = Basically Available, Soft state, and Eventual consistency
online analytical processing (OLAP)
generated from data in other databases and are often called data warehouses
databases that have been primarily optimized for analysis (for data retrieval purposes)
However, both the terms OLTP and OLAP have become outdated.
Types of Relational Databases
Row-based/Columnar databases
Row-based indexes
Columnar indexes
Storage on disk
Row by row
Column by column
Read/write
Best at random reads and writes
Best at sequential reads and writes
Best for
Returning full rows of data based on a key
Returning aggregations of column values
Implementation
Transactional systems
Analytical processing
Data compression
Low to medium compression can be achieved
High compression is the norm
Distributed/Single-homed databases
Distributed databases are collections of data systems distributed across multiple physical locations.
Single-homed databases are databases where all of the data is stored in the same physical location.
Separated storage and computing systems
databases where less relevant data is stored remotely, and relevant data is stored locally for analysis.
Combined systems
database systems that store and analyze data in the same place.
Factors of database performance
Workload
= the combination of transactions, queries, data warehousing analysis, and system commands being processed by the database system at any given time.
Throughput
= the overall capability of the database's hardware and software to process requests.
Resource
= the hardware and software tools available for the database
Optimization
= Maximizing the speed and efficiency with which data is retrieved in order to ensure high levels of database performance.
optimization for data reading
indexing, partitioning, caching
queries
Consider the business requirements
Avoid using SELECT* and SELECT DISTINCT: Using SELECT* and SELECT DISTINCT causes the database to have to parse through a lot of unnecessary data. Instead, you can optimize queries by selecting specific fields whenever possible.
Use INNER JOIN instead of subqueries
Contention
Contention occurs when two or more components attempt to use a single resource in a conflicting way.
Database Consistency
There are two methods that databases implement for consistency: ACID and BASE.
ACID (Atomicity, Consistency, Isolation, and Durability)
= a method for maintaining consistency and integrity in a structured database
BASE (Basically Available, Soft state, Eventually consistent)
= a method for maintaining consistency and integrity in a structured or semistructured database