Amazon SageMaker
Train a custom model with Amazon SageMaker
- configure dataset (Amazon S3 URL, computing instance, or path for storing the training code in Amazon Elastic Container Registry (ECR)) & evaluation metrics (Amazon CloudWatch Logs)
- configure hyperparameters
- provide training script
- fit the model
Features
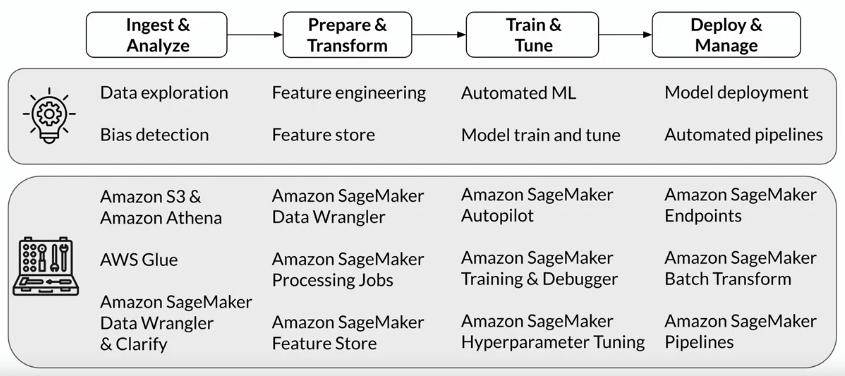
Machine learning workflow
-
SageMaker Data Wrangler
- connect pandas DataFrames and AWS data services
- load and upload data
-
SageMaker Clarify
-
SageMaker Processing Jobs
-
SageMaker Feature Store
- store and serve features
- reduce skew
- real time & batch
-
SageMaker Autopilot
- cover all steps in AutoML: ingest & analyze data -> prepare & transform data -> train & tune model
- automatically generate notebooks (candidate generation notebook (provides links to the data preprocessor Python scripts, the algorithms, and the algorithm hyperparameters selected by Autopilot), data exploration notebook) and codes
-
SageMaker Debugger
- capture real-time debugging data during model training in Amazon SageMaker
- system metrics: CPU&GPU utilization, data I/O metrics
- framework metrics:
- convolutional operations in forward pass
- batch normalization operations in backward pass
- data loader processes between steps
- gradient descent algorithm operations
- output tensors: scalar values (accuracy and loss); matrices (weights, gradients, input & output layers)
- if bugs, actions can be taken via
- Amazon CloudWatch Event: send SMS etc
- Amazon SageMaker Notebook: analyze
- Amazon SageMaker Studio: visualize
- capture real-time debugging data during model training in Amazon SageMaker
-
SageMaker Hyperparameter Tuning
- steps: create an Estimator -> define the combination of hyperparameters -> start a SageMaker hyperparameter tuning job -> analyze results and select the best model candidate
- a "warm start" feature: reuses results from a previous hyperparameter training job
- scenarios:
- you want to change the hyperparameter tuning ranges from the previous job -> use type "identical data and algorithm"
- you want to add new hyperparameters -> use type "transfer learning"
- scenarios:
-
ML Model Deployment with SageMaker
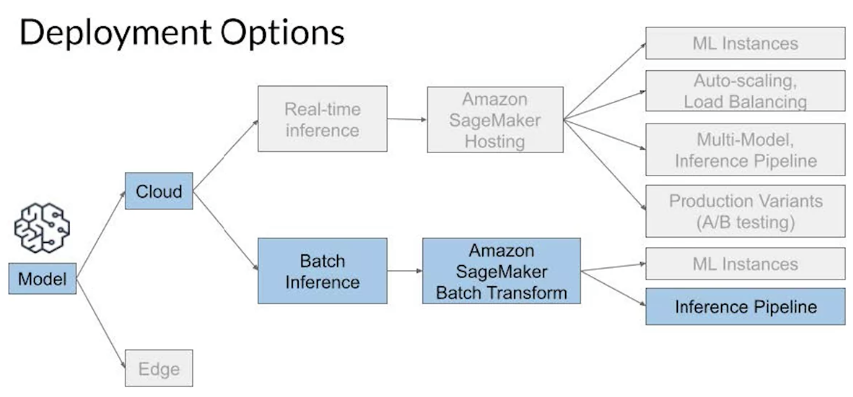
- SageMaker Endpoint
- real-time prediction ML Model Deployment#^b2b283
- auto-scaling
- pipeline of creating SageMaker production variants with Endpoint:
- construct Docker Image URI -> create SageMaker models -> create production variants -> create endpoint configuration -> create endpoint
- pipeline of creating SageMaker production variants with Endpoint:
- SageMaker Batch Transform
- batch prediction ML Model Deployment#^50c5c9
- SageMaker Endpoint
-
SageMaker Pipelines
- SageMaker model registry: for Machine Learning Systems Design#^8e6855
-
SageMaker Model Monitor
-
SageMaker Ground Truth
- for Data preprocessing#Data labelling
- job workflow: setup input data -> select labelling task -> select human workforce -> create task UI
- human workforce options: Amazon Mechanical Turk/Private/vendor
-
SageMaker Projects
- integrates automatically with SageMaker Pipelines and SageMaker model registry
- create MLOps solutions to orchestrate and manage your end to end machine learning pipelines, while also incorporating CI/CD practices
-
SageMaker Managed Spot Training: for Machine Learning Systems Design#Checkpointing
-
Amazon SageMaker BlazingText: unlike Natural Language Processing#^ff7c47, it is a word2vec model