Convolutional Neural Networks
How it works
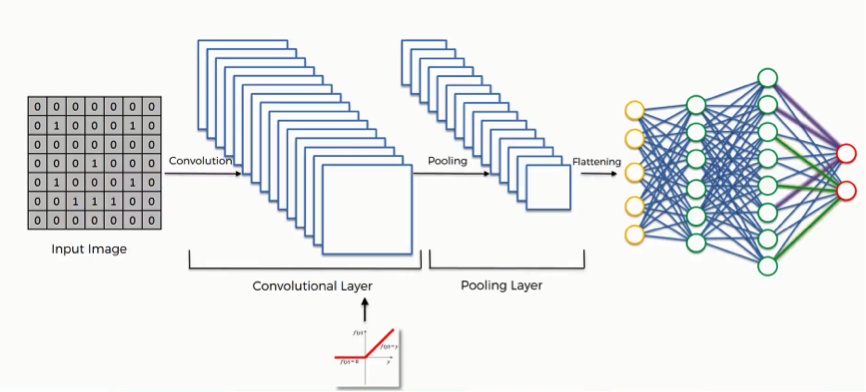
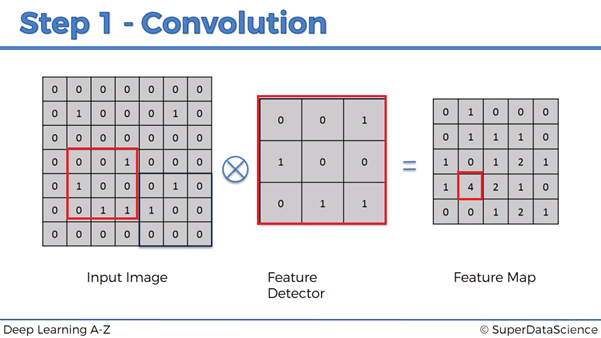
1. Convolution operation
- convolution operations can make the detector dependent on features and independent of locations -> coarse and invariant detection
- stride (Convolutional Neural Networks#Stride) = the moving step size of the feature detector: usually 2
- feature detector = kernel = filter: usually 3x3, but other models such as AlexNet use 7x7
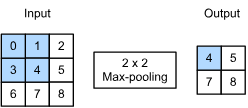
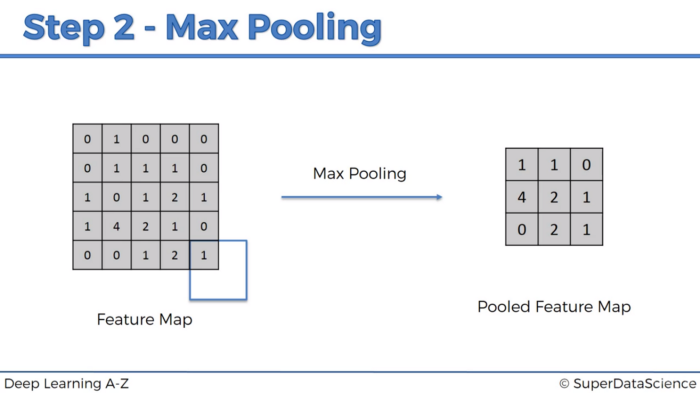
2. Pooling
- Pooling = down-sampling = aggregate results over a window of values
- can reduces features and is more robust to overfitting
- types
- max pooling: represent a subregion by max activation map
- global pooling: reduce spatial dimension to 1
- aum pooling, Avg Pooling(~subsampling)
- max pooling: represent a subregion by max activation map
- max-pooling is preferable to average pooling, as it confers some degree of invariance to output
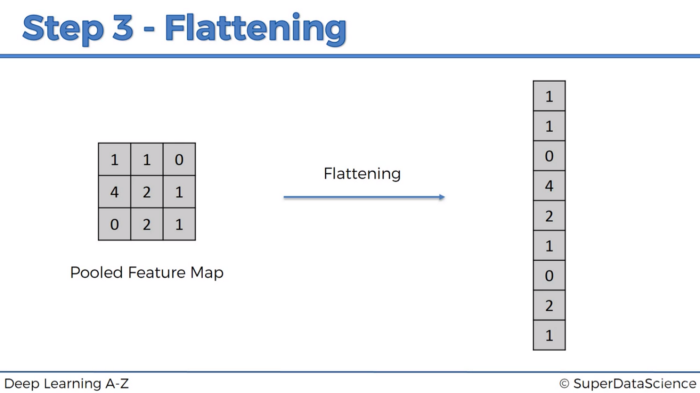
3. Flattening
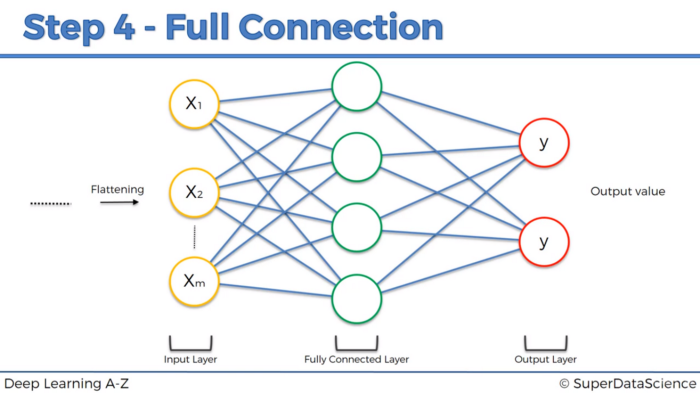
4. Full connection
The flattened vectors are propagated into an ANN as the input layer
Size calculation
Assuming that the input shape is
Techniques can also change the output shape:
Padding
- Padding can increase the height and width of the output
- padding = add extra pixels of filler around the boundary of our input image, thus increasing the effective size of the image
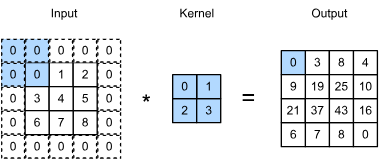
- if we add a total of
rows of padding (roughly half on top and half on bottom) and a total of columns of padding (roughly half on the left and half on the right), the output shape will be - In many cases, we will want to set
and to give the input and output the same height and width
Stride
- Stride can reduce the resolution of the output
- stride = the number of rows and columns traversed per slide
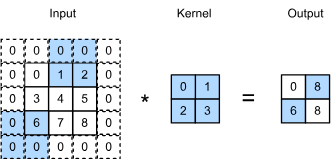
- when the stride for the height is
and the stride for the width is , the output shape is