Dimensionality Reduction
There are two types of Dimensionality Reduction techniques:
- Feature selection
- Feature extraction
Feature Selection
- Backward Elimination, Forward Selection, Bidirectional
- Elimination, Score Comparison
Feature Extraction
PCA vs. LDA
-
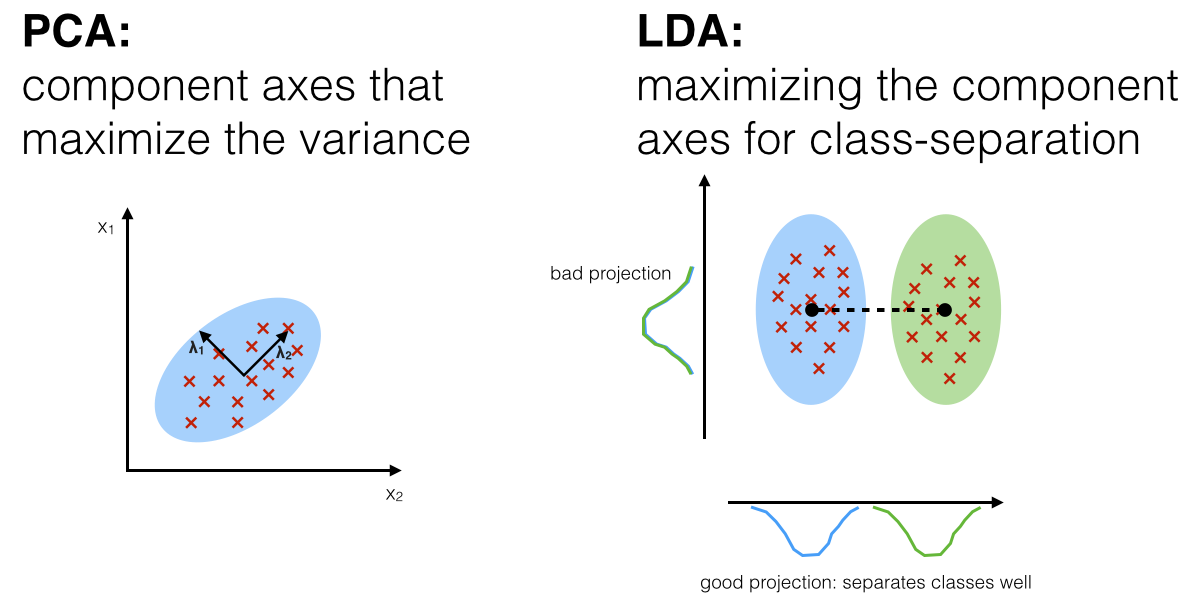
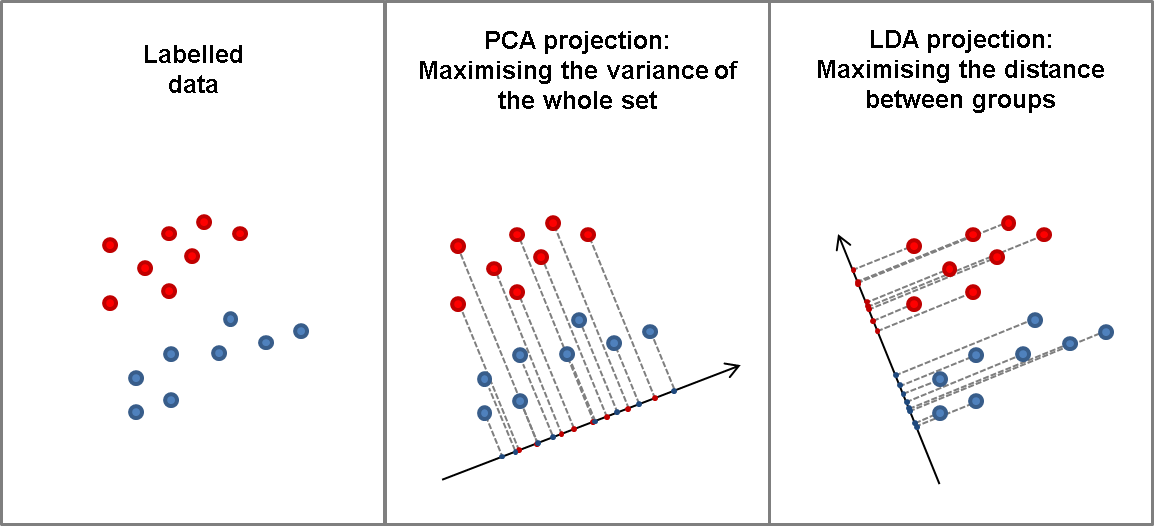
PCA capture the variability; LDA class separation
-
PCA is unsupervised; LDA is supervised (because of the relation to the dependent variable)
-
How LDA works exactly
- it creates new axes to maximize the class-separation, step by step (2-class example):
- maximize the distance between class means
and - minimize the variation (which LDA calls "scatter") within each class
and - compute
(= ) and LDA should maximize it - if more than 2 classes, e.g. there are 3 classes, the value to be maximized will be
- maximize the distance between class means
- it creates new axes to maximize the class-separation, step by step (2-class example):
t-SNE
- = T-Distributed Stochastic Neighbor Embedding
- t-SNE takes high-dimensional data and reduces it to a low-dimensional graph (2-D typically)
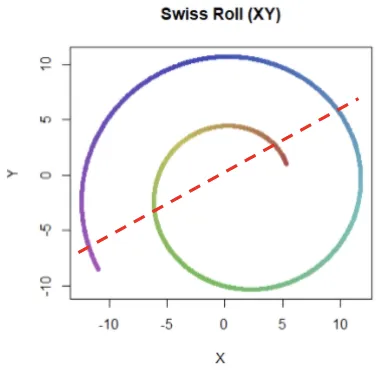
- Unlike PCA (which is linear), t-SNE can reduce dimensions with non-linear relationships (such as “Swiss Roll” non-linear distribution)
- it calculates a similarity measure based on the distance between points instead of trying to maximize variance.