LLM optimization techniques
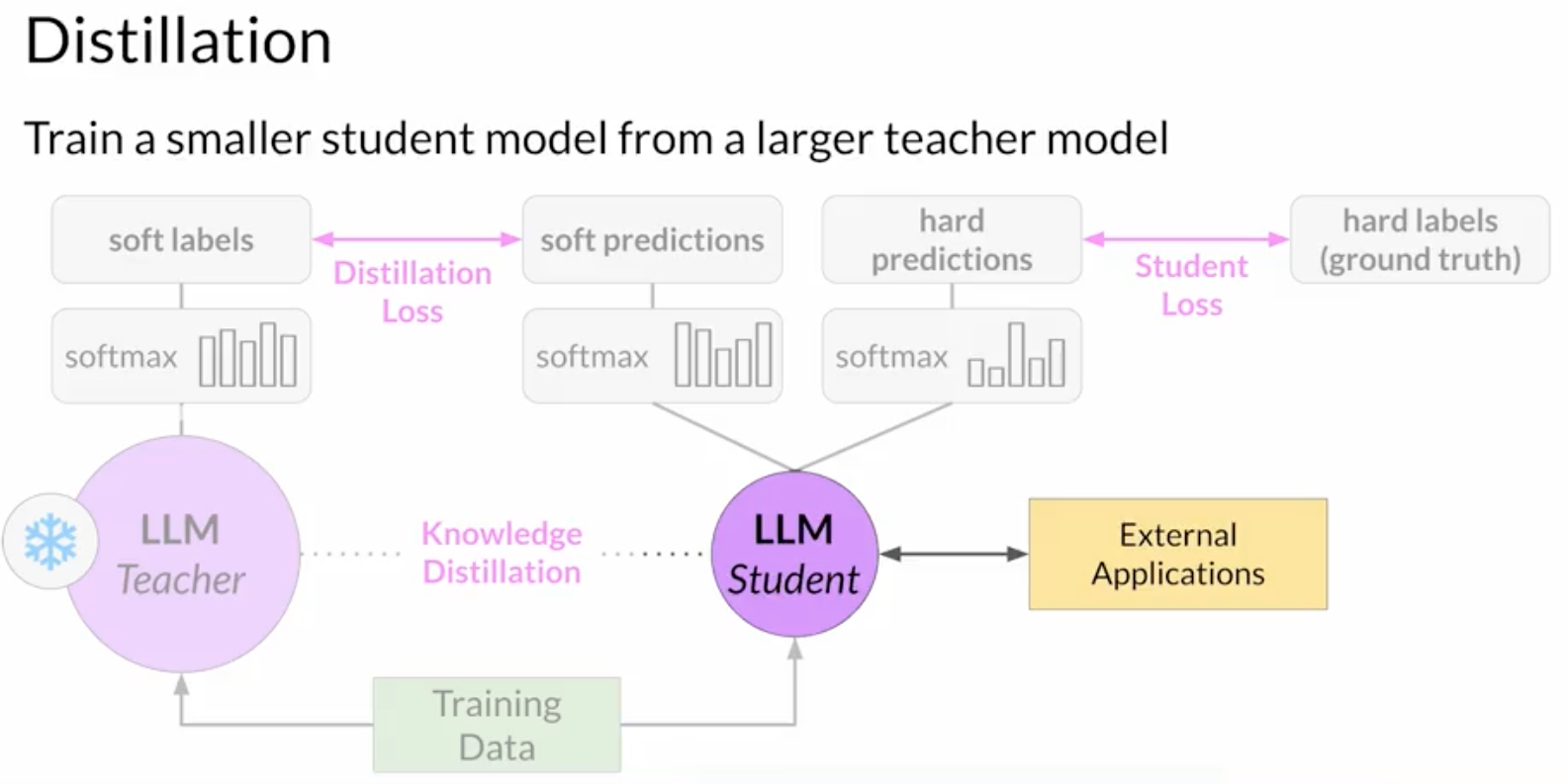
distillation
- = a larger teacher model train a smaller student model.
- the student model learns to statistically mimic the behavior of the teacher model
- either just in the final prediction layer
- or in the model's hidden layers as well
- typically effective for encoder-only models
-
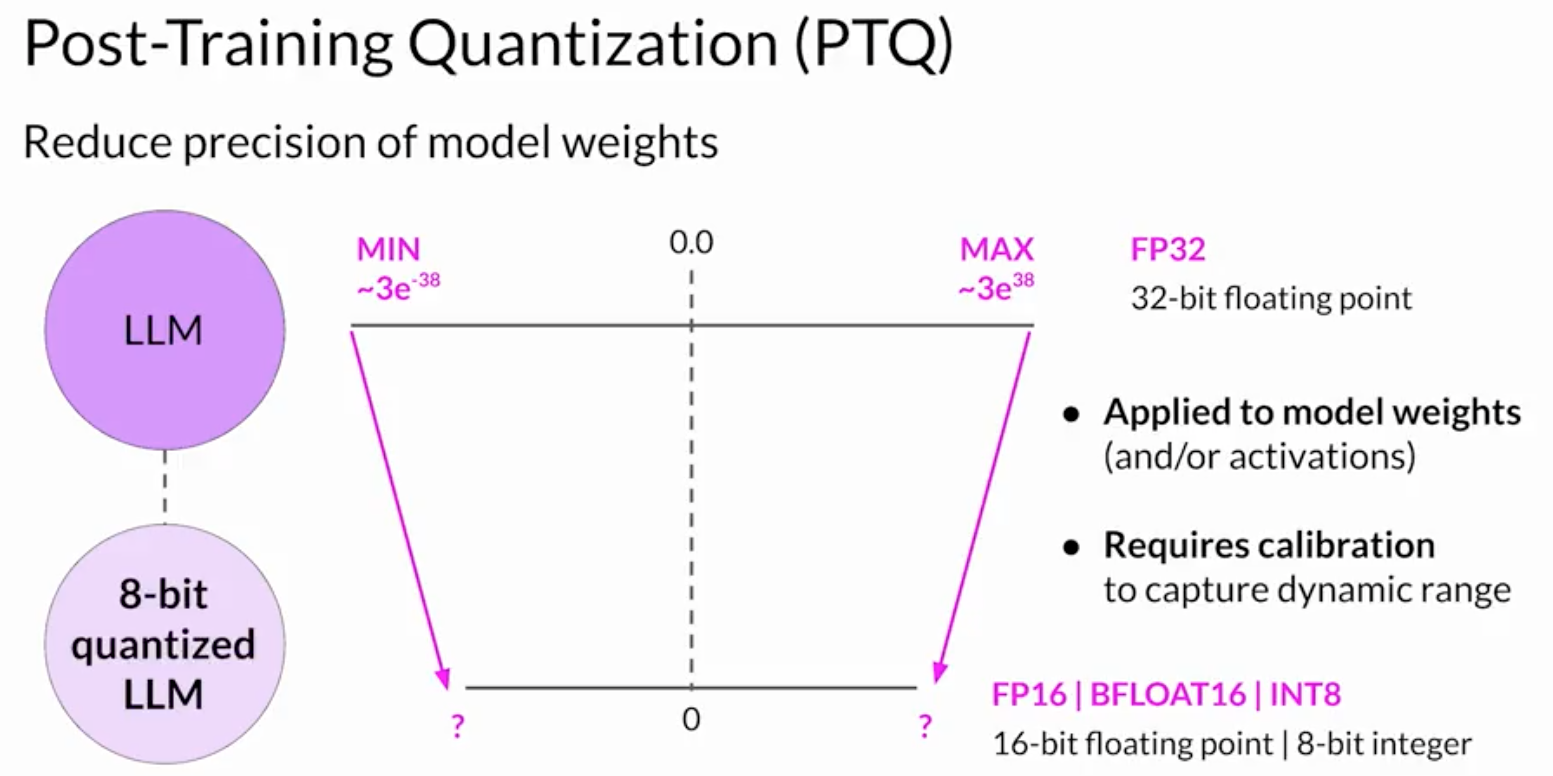
quantization
- = reduce weight's precision
- example: Post-Traning Quantization (PTQ)
-
pruning
- = remove model weights with values close or equal to 0
- pruning methods
- full model re-training
- PEFT/LoRA
- Post-training
- in theory vs. in practice
- in theory, it can reduce model size and improve performance
- in practice, only small % in LLMs are 0-weights