Machine Learning All-in-one
What is machine learning?
- Arthur Samuel 1949 (1901 -1990): Machine Learning is a field of study that gives Computers the ability to learn without being explicitly programmed.
- Tom Mitchell 1997 (1951 -): Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if it is performance on T, as measured by P, improves with experience E.
Full Cycle of a ML project
- define project
- define and collect data (Data Sampling) + Data preprocessing
- train model: training, Error analysis & iterative improvement -> loop between 2 and 3 until your model is done
- deploy in production (Machine Learning Systems Design): deploy, monitor, and maintain system -> back to 3 and/or 2 if needed
Types of Machine Learning
ML Algorithms Cheat Sheet
[[ML+Algorithms+Cheat+Sheet.pdf]]
Supervised Learning
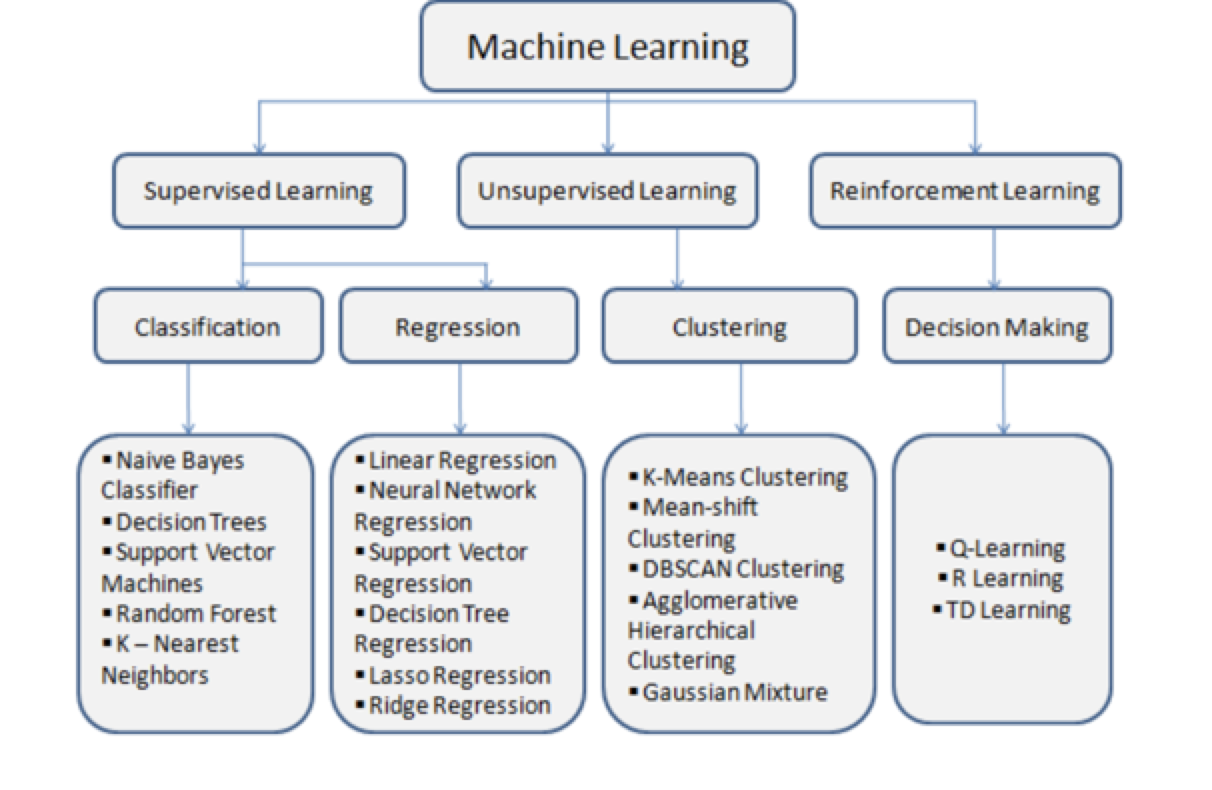
Classification
- linear
- Logistic Regression
- Support Vector Machine SVM: Support Vector X#Support Vector Machine SVM
- non-linear
- Kernel SVM: Support Vector X#Kernels SVM
- K-Nearest Neighbor (k-NN)
- Naive Bayes
- Decision Tree Classification: Decision Tree & Random Forest#Decision Tree
- Random Forest Classification: Decision Tree & Random Forest#Random Forest
- Pros and Cons
- Multi-class vs. Multi-label Classification
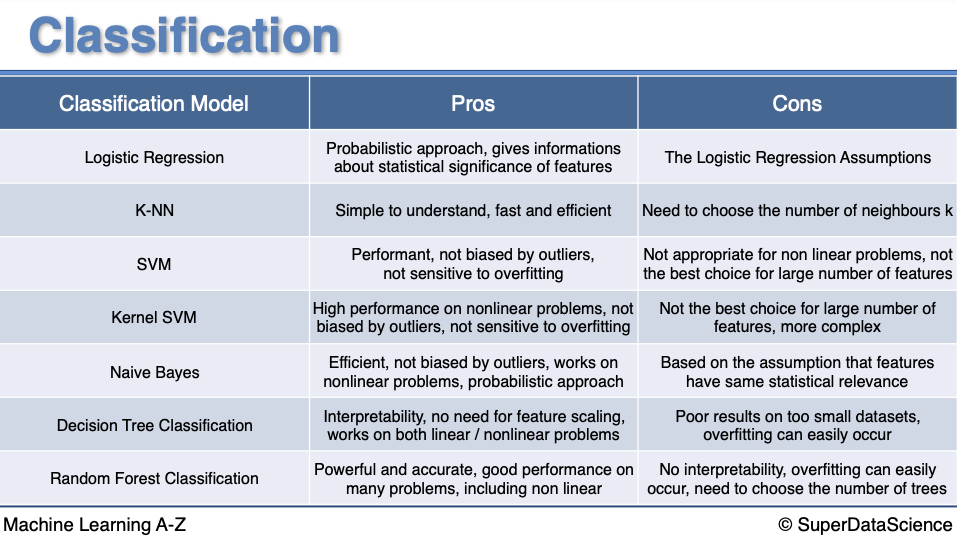
Regression
- Types
- Linear Regression
- Polynomial Regression
- Regularized regression
- Lasso regression: Cost Functions#^ed4ab0
- Ridge regression: Cost Functions#^aef45a
- Support Vector Regression (SVR) Support Vector X#^46e7f9
- Decision Tree Regression: Decision Tree & Random Forest#Decision Tree
- Random Forest Regression: Decision Tree & Random Forest#Random Forest
- Pros and Cons
Unsupervised Learning
Note
The distinction between unsupervised versus self-supervised learning can be blurry sometimes. Roughly:
- Unsupervised learning attempts to learn representations without labels by not using any targets of any sort during training, e.g. by using correlations in activity between units.
- Self-supervised learning attempts to learn representations without labels by using the data itself to generate targets, e.g. generating targets using the next word in a sentence
- Put another way, self-supervised learning looks a lot like supervised learning in code, but there is a big difference related to the following question: do you as a machine learning researcher have to actually ask someone to label the data or not.
Density estimation
Anomaly detection
Clustering
-
Types
- Centroid-based Clustering: K-Means Clustering
- Connectivity-based Clustering: Hierarchical Clustering
- Density-based Clustering: DBSCAN
- Graph-based Clustering: Affinity Propagation
- Distribution-based Clustering: Gaussian Mixture Model
- Compression-based Clustering: Spectral Clustering
-
Pros and Cons
| Clustering Model | Pros | Cons |
|---|---|---|
| K-Means | interpretability; works well on even-sized and globular-shaped data | need to predefine the number of clusters; not appropriate for outliers; low computation efficiency |
| Hierarchical Clustering | no need to predefine the number of cluster; high computation efficiency; works well on high dimensional data | not appropriate for large data |
| DBSCAN | no need to predefine the number of cluster; can determine arbitrarily-shaped clusters; can detect outlier | unstable performance (sensitive to density units parameter) |
| Affinity Propagation | no need to predefine the number of cluster | low computation efficiency |
| Gaussian Mixture Model | highest computation efficiency; ensure clusters to follow Gaussian distributions | not appropriate when insufficient data in each cluster |
| Spectral Clustering | high computaion efficiency | need to predefine the number of clusters |
Association Rule Learning
- Apriori: Association Rule Learning#Apriori
- Eclat: Association Rule Learning#Eclat
Dimensionality Reduction
- Feature Selection
- Feature Extraction: transform datasets with more than 3 features (high-dimensional) into typically a 2D or 3D
- Principal Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- Kernel PCA
- Quadratic Discriminant Analysis (QDA)
- T-Distributed Stochastic Neighbor Embedding (t-SNE, Dimensionality Reduction#^53a070)
- Uniform manifold approximation and projection (UMAP): similarly to t-SNE, but also for general non-linear dimension reduction
- Autoencoders
Outlier Detection
Ensemble Learning
- Bagging: Ensemble Learning#Bagging (Bootstrap Aggregating)
- Boosting: Ensemble Learning#Boosting
Reinforcement Learning
- Decision making
- Q-Learning: Reinforcement Learning#Q-Learning
- R Learning
- TD Learning
- Upper Confidence Bound: Reinforcement Learning#Upper Confidence Bound
- Thompson Sampling: Reinforcement Learning#Thompson Sampling
Deep Learning
Important
- deep learning = training large neural network
- deep learning is most powerful in supervised learning
- applications: Advertisement, Images vision, Audio to Text, Machine translation, Autonomous Driving
- Practical Aspects in Deep Learning
Model Selection & Improving
- Cross-Validation
- tuning on parameters/Hyperparameter Tuning
- randomized search
- grid search
- Ensemble Learning
ML Model into production
Best Practice: Be careful about common issues
sample bias
- selection bias
- response bias
- real-business scenario: activity bias (social media content), societal bias (human generated content), selection bias (generated by the model itself to form a feedback loop)
data drift/shift: data distribution shifts
- covariant drift: data distribution of independent variables shifts
- label/prior drift:
- data distribution of target variables shifts (the output distribution changes but, for a given output, the input distribution stays the same)
- concept/posterior drift:
- the definition of label itself changes based on a particular feature (the input distribution remains the same but the conditional distribution of the output given an input changes)
- general data distribution shifts
- feature change
- label schema change
Endogeneity
- = a situation where there is a correlation between the predictor variables and the error term in a statistical model.
- e.g. Rich becomes richer, poor becomes poorer.